Enrichment Analysis - gprofiler
gprofiler provide a great tool for performing enrichment analysis, it also has associated tools for ID conversations and Orthology searching. As well as interrogating enrichment for (Gene Ontology)[http://geneontology.org/] terms and pathways (it uses (reactome)[https://reactome.org/] it also exploits physical position linked properties such as transcription factor binding sites and miRNSA binding to provide additional evidence of linkages between DEGs. Another function that is exceptionally useful is the ability to provided two gene lists and compare the enrichment side-by-side. To do this place ‘> title of list 1’ before the first list and ‘> title of list 2’ (and so on for as many list as you want) before submitting your enrichment analysis Note the essential element is the ‘>’ sign but also remember to select < Run as multiquery > if you want this option..
- Load you DEG list
Paste you DEG list into the box and click on < Run query > (I suggest you select Benjamin-Hochberg FDR under Advanced options)
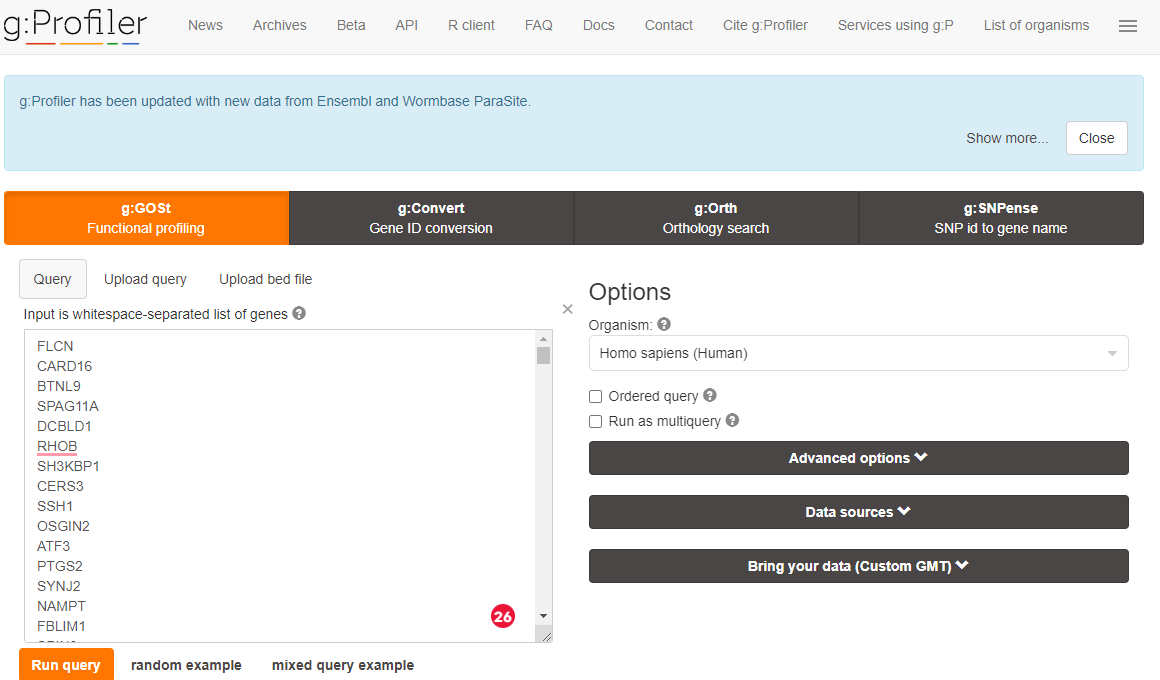 gprofiler upload data
gprofiler upload data
You may be asked if you wish to confirm gene identified - if you are accept the selected options.
- Review Enrichment
You will be presented with and enrichment summary.
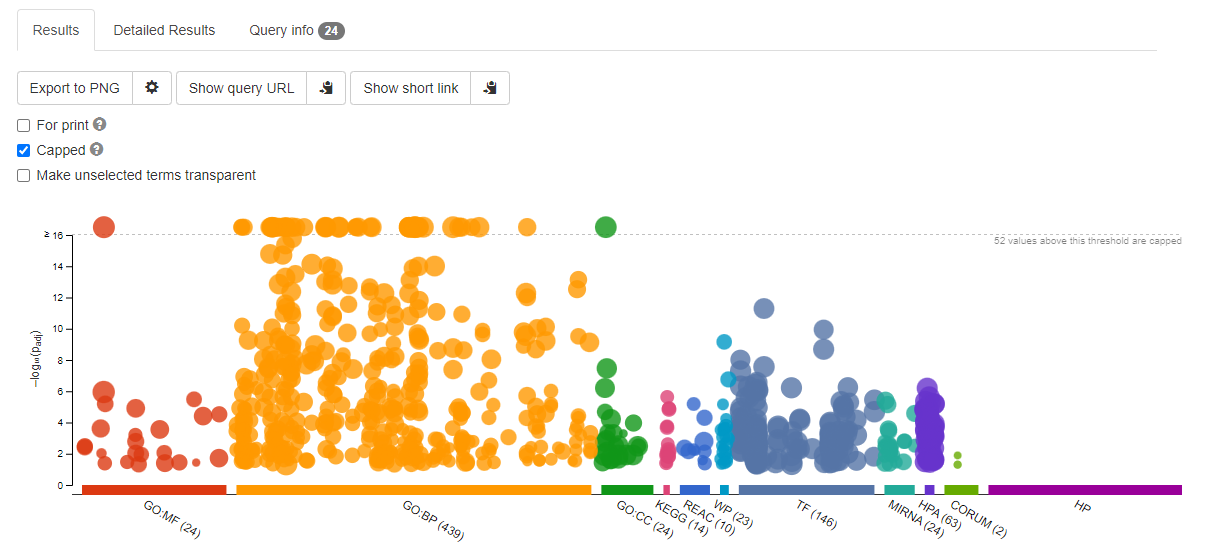 Enrichment Summary
Enrichment Summary
Here the y-axis is -log10(adjPValue) - so the larger the number the more improbably the functional representation is there by random. The size of the symbols represent the number of genes in each category.
Now select < Detailed Results > this is a tab that is displayed about halfway down the page
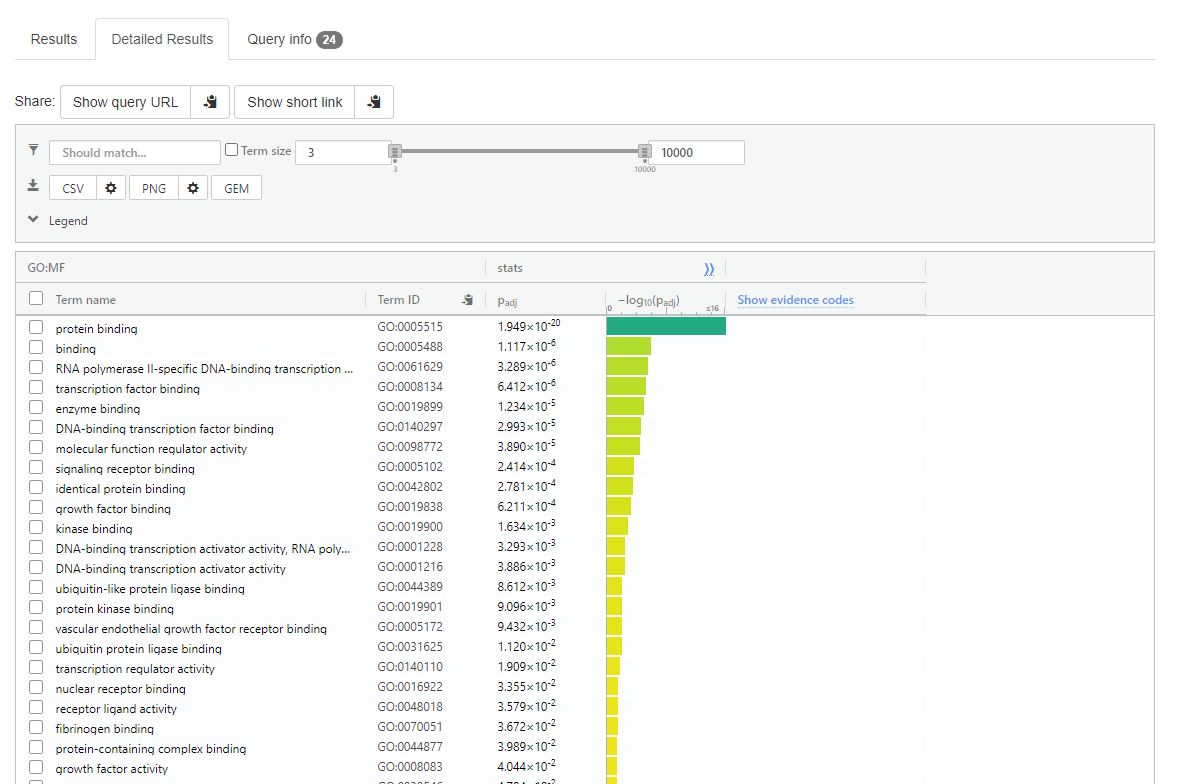 gprofiler detailed results
gprofiler detailed results
Note:
Adjusted p-value if give next to each term
Top of the detailed results page there is ‘CSV’ option to download the data into a spreadsheet format.
- Consider the Transcription Factor enrichment.
Gene regulation is at the heart of DEGs - co-regulated gene should should have direct or indirect regulatory network moderated through conserved transcription factor binding sites.
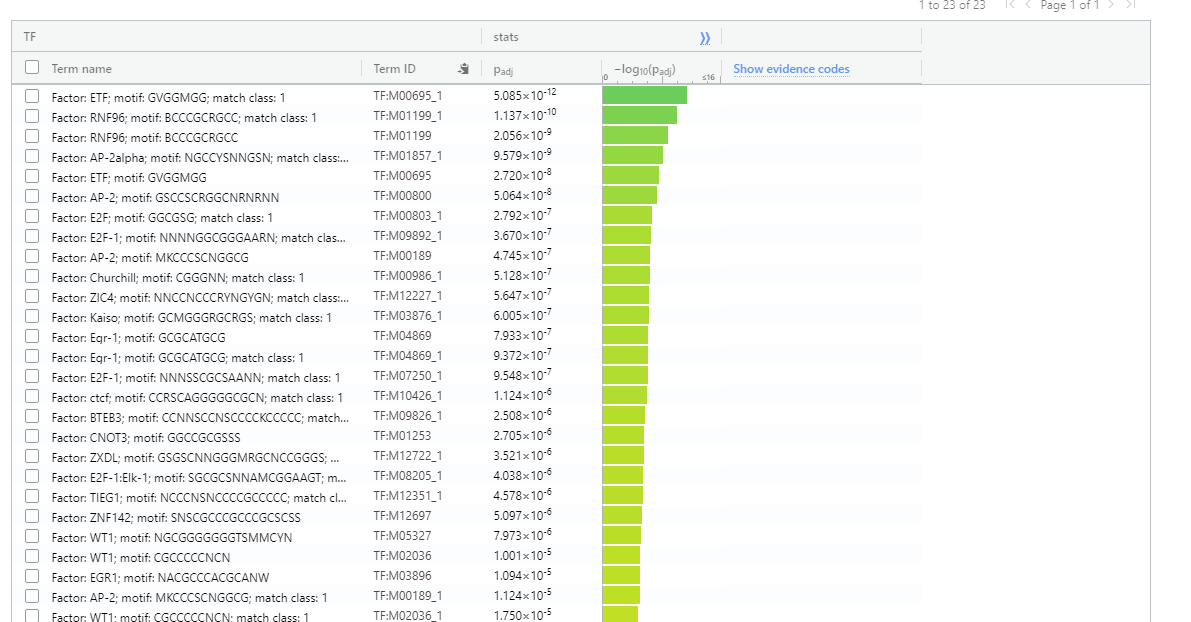 Transcription Factor enrichment
Transcription Factor enrichment
gprofiler panopto
Database for Annotation, Visualization and Integrated Discovery - DAVID
David Web site - https://david.ncifcrf.gov/
Gene Enrichment Analysis with David
[David - Database for Annotation, Visualization and Integrated Discovery] (https://david.ncifcrf.gov/) was the tool to use for gene enrichment from 2005 - 2016 but the database it hosted became out of date due to a break in the research groups funding. From 2016 (gprofiler)[https://biit.cs.ut.ee/gprofiler/gost] and (stringdb)[https://string-db.org/] have been prefered because they have been kept upto date. However, DAVID was refunded and a 2021 update means it is back to being maintained. Although there will not be time to explore it in our workshop the following workshop and video is there to support anyone wanting to explore its functionality.
1. Start analysis and upload you data
Select < start analysis >
Paste in you gene list (1) in box (A) and, select identifier (2), and identify as a Gene List (3). Select your species (2a) . In more nuanced analysis you may wish to define your own background - this is useful when working with non-model organisms or if your starting population does not represent the entire genome.
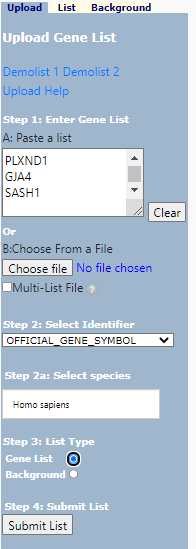 DAVID Upload
DAVID Upload
now select < Submit List >
2. Generate Functional Analysis of gene list
If you have used a non-regulate gene identifier or it does not recognize the identifier type you have used it may ask you to convert the identifiers - check the programs suggestion - it is usually good but you should check.
Select < Functional Annotation Tool >
You will now be give a annotation summary as shown below:
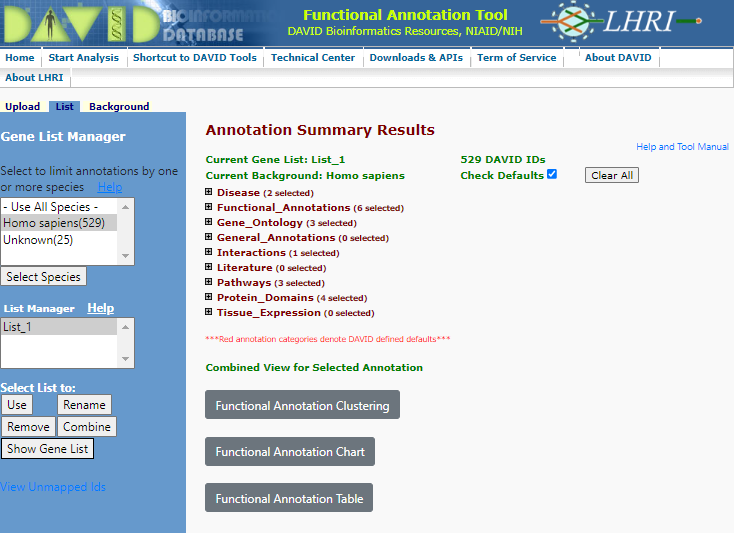 Annotation Summary
Annotation Summary
You will see a range of categories for which the functional annotation has been performed. The analysis told has not only cross referenced the gene list against a range of functional databases it has also analysed the gene co-appearance in citations (Literature), links to disease (Disease) and Interactions agonist other linkages.
3. Review Gene Ontology Enrichment
Let us consider the functional enrichment using (Gene Ontology)[http://geneontology.org/]. Gene Ontology categorizes gene products using three distinct characteristics - Molecular Function (biochemistry of the product), Cellular Component (where it appears in the cell), and the Biological Processes - see more about these classification by reviewing the (Gene Ontology Overview documentation)[http://geneontology.org/docs/ontology-documentation/]. Although ontologies are hierarchical, they are not a simple classification system, they not only allow for gene products to be involved with multiple processes the relationship between elements in the hierarchy are closely defined. The ontology also allows for classification to be as specific or detailed as knowledge allows ie if a protein is a transporter but what it transports is not known it will be defined by a mid-level term ‘transporter’ but if it is known to transport Zn it will be classified at a ‘Zinc transport’ as well as a ‘transporter’. Enrichment analysis uses fisher exact test (see about) to calculate the enrichment at each of these ‘levels’ - although I usually choose to look at the integrated data summarized under the ‘GOTERM_[BP/CC/MF]_DIRECT’.
click on the + next too the < Gene_Ontology > category
Select < Chart > right of the GOTERM_BP_DIRECT
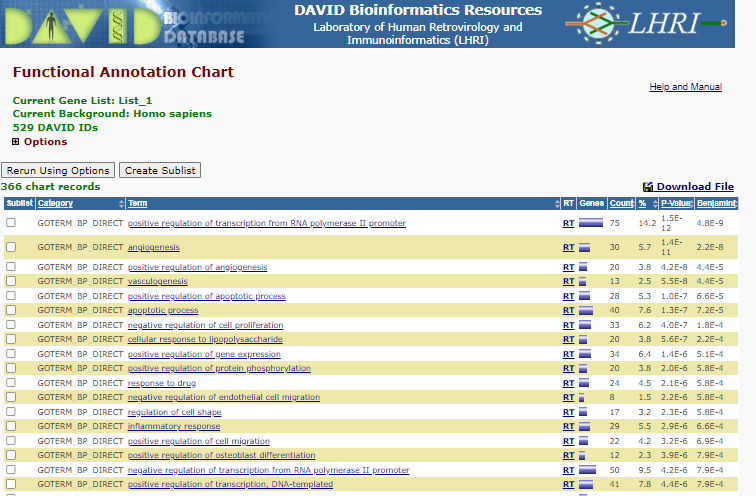 BP Enrichment
BP Enrichment
Note the P-value and benjamini correct p-value displaying the like hood that those specific Go terms are represented by random - i.e. lost the P-value the less likely the representation of the term is a random select , therefore the more likely the term is enriched.
To see the list of gene involved in for instance ‘positive regulation of osteoblast differentiation’ click on the blue bar under the ‘Genes’ column.
This is the list you will see:
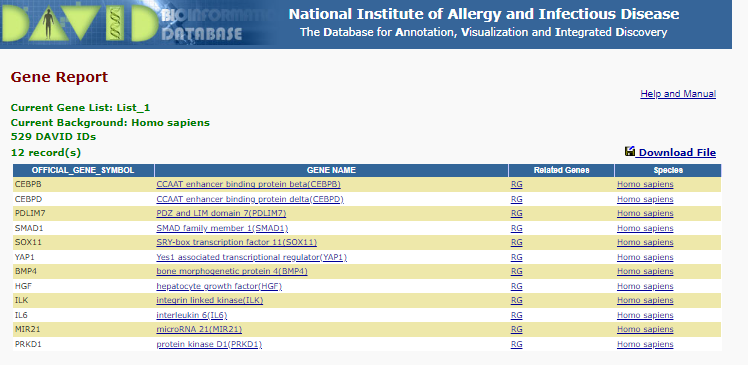 positive regulation of osteoblast differentiation
positive regulation of osteoblast differentiation
Now review enrichment for Cell Component and Molecular Function.
4. Pathway analysis
click on the + next too the < Pathways > category
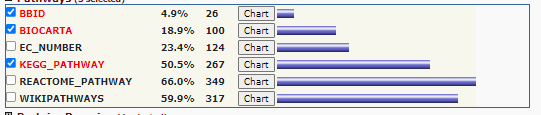 Pathway Options
Pathway Options
Select < Chart > right of the KEGG
 KEGG Enrichment
KEGG Enrichment
You will see a list of enriched pathways - Note the P-value and benjamini correct p-value displaying the like hood that those specific pathways are represented by random - i.e. lost the P-value the less likely the representation of the pathway is a random select, therefore the more likely the pathways is enriched.
click on the < TNF Signalling Pathway >_ in the term column
This will display the pathway with the terms that are present in the list shown with red stars or highlight by redtext below the figure.
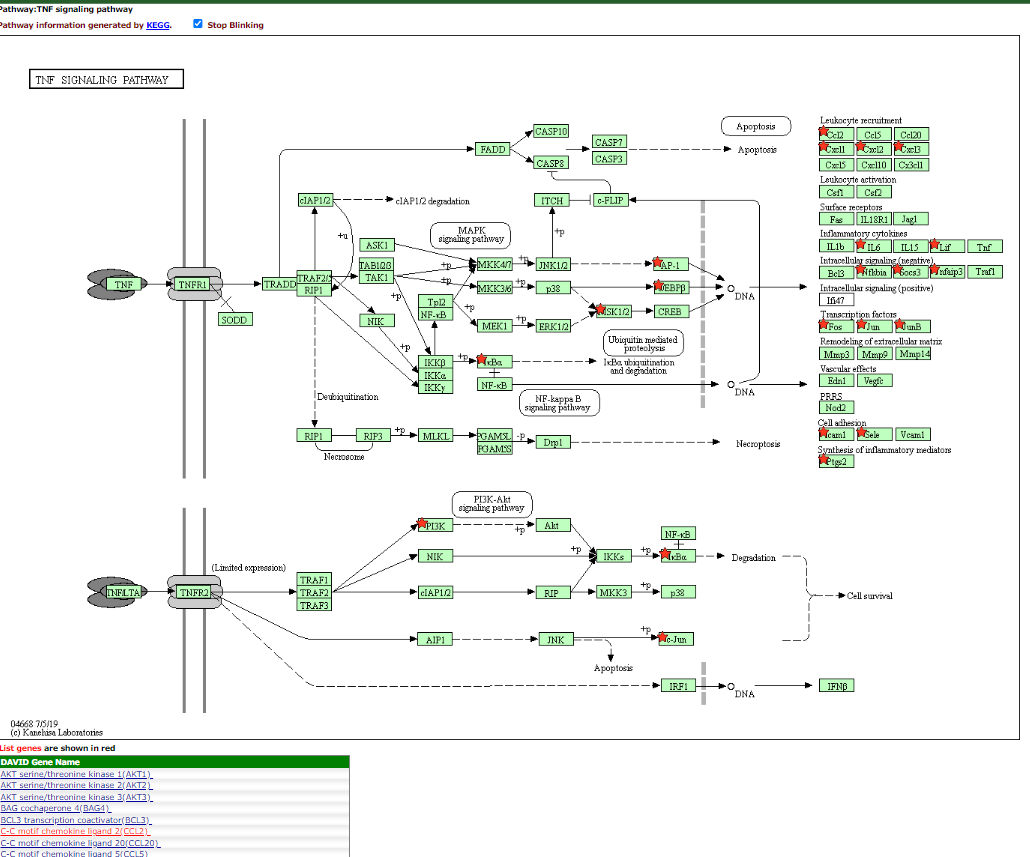 TNF Signalling Pathway
TNF Signalling Pathway
Explore some more pathways
5. Functional Annotation Clustering
DAVID attempts to summarise enrichment between categorization systems using a tool it terms - Functional annotation clustering. If you select this for you current data set. you will be provided with the following clusters:
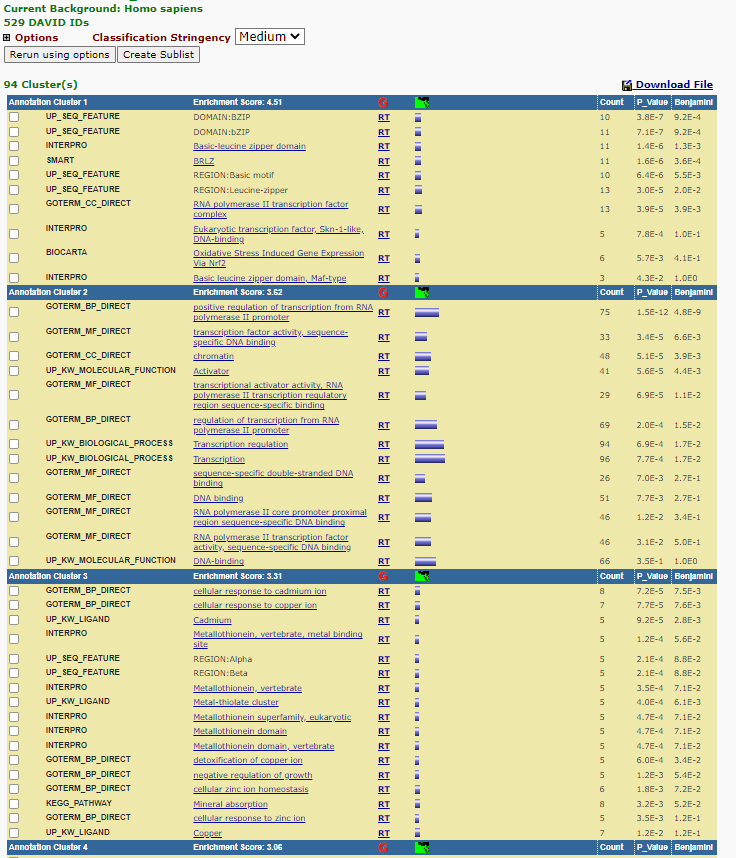 Functional Annotation Clustering
Functional Annotation Clustering
Each cluster is assigned an enrichment score under which ‘terms’ that are enriched under different classification systems are displayed grouped together. Each ‘grouping’ is given a ‘Enrichment Score’ the larger the enrichment score the higher the score the more likely that cluster is being enriched. Note that the is a ‘Classification Stringency’ pull down menu that allows you to define the strength of associated of the term being grouped together.
For annotation Cluster 6 (which contains lots of Metallothionein/cadimum associated terms) there is a small green and black box - after the Enrichment Score and the ‘G’ - click on this box. This brings up a cluster matrix showing the gene gene products on the Y-axis and the classification ‘vlasses’ on the X-axis.
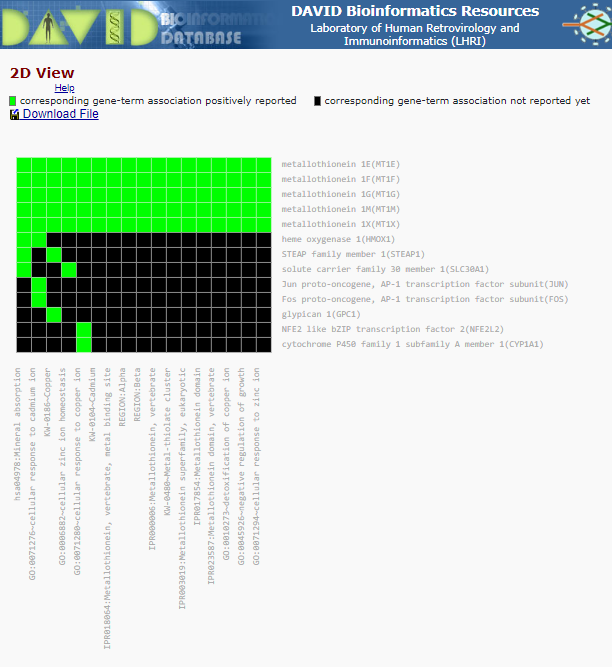 Cluster Matrix
Cluster Matrix
Enrichment with David Panopto
STRING
- Login to String-db
Open String-db and login using an appropriate account
- Upload your data
Select < My data > from top menu
Select < create new gene set > under < Your stored gene sets >
Give you Gene List a Name, select Homo sapiens as species and past in your gene symbols
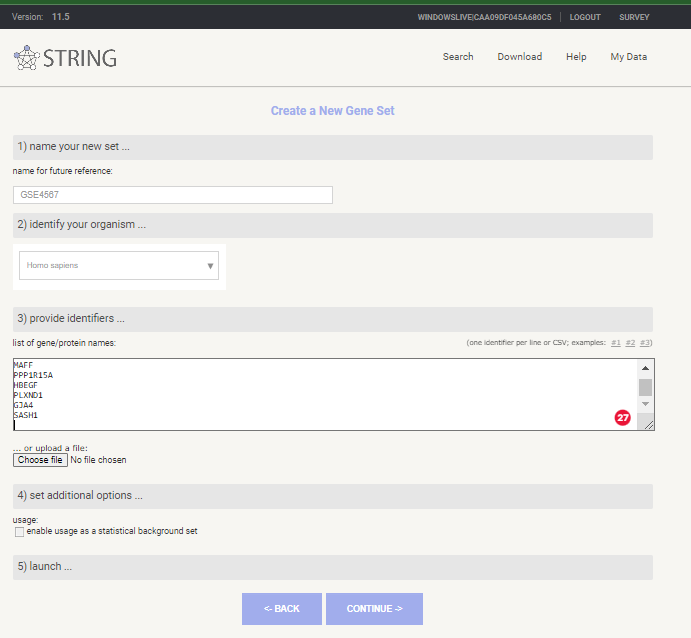 New Gene Set in STRING-db
New Gene Set in STRING-db
Select < continue >
if asked to review mappings < please review the mappings … > select continue
- Explore Gene Enrichment
Review stored Gene set and select < analyse >
 Stored Gene Set in STRING-db
Stored Gene Set in STRING-db
Review Enrichment analysis
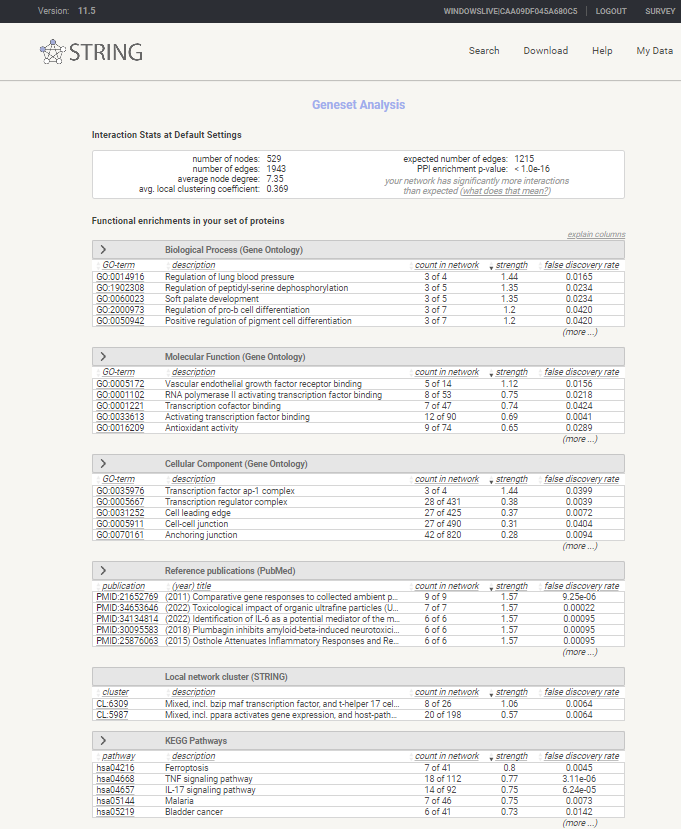 Enrichment analysis in STRING-db
Enrichment analysis in STRING-db
- Create you Gene Network
Return to you dataset and now select < show >
Select < view as a interactive network >
You will now see a very large and detailed network - go to bottom on page and select settings and change to match the following settings. The select < update >
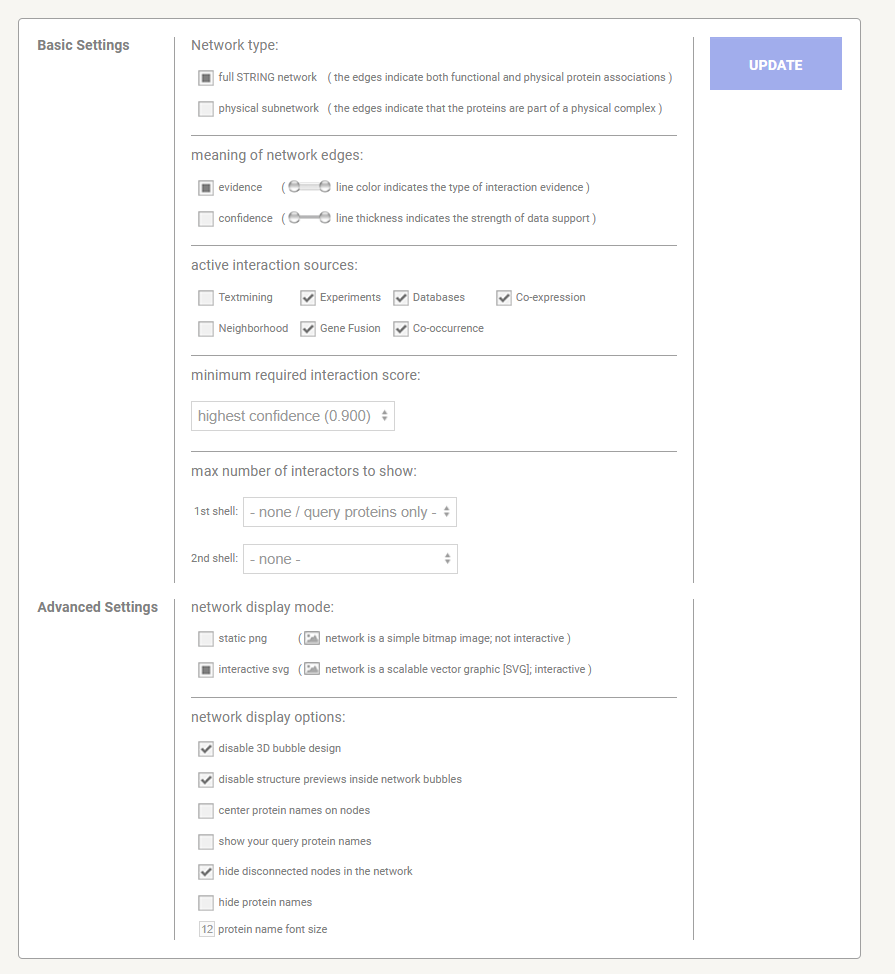 STRING-db Settings
STRING-db Settings
First_network
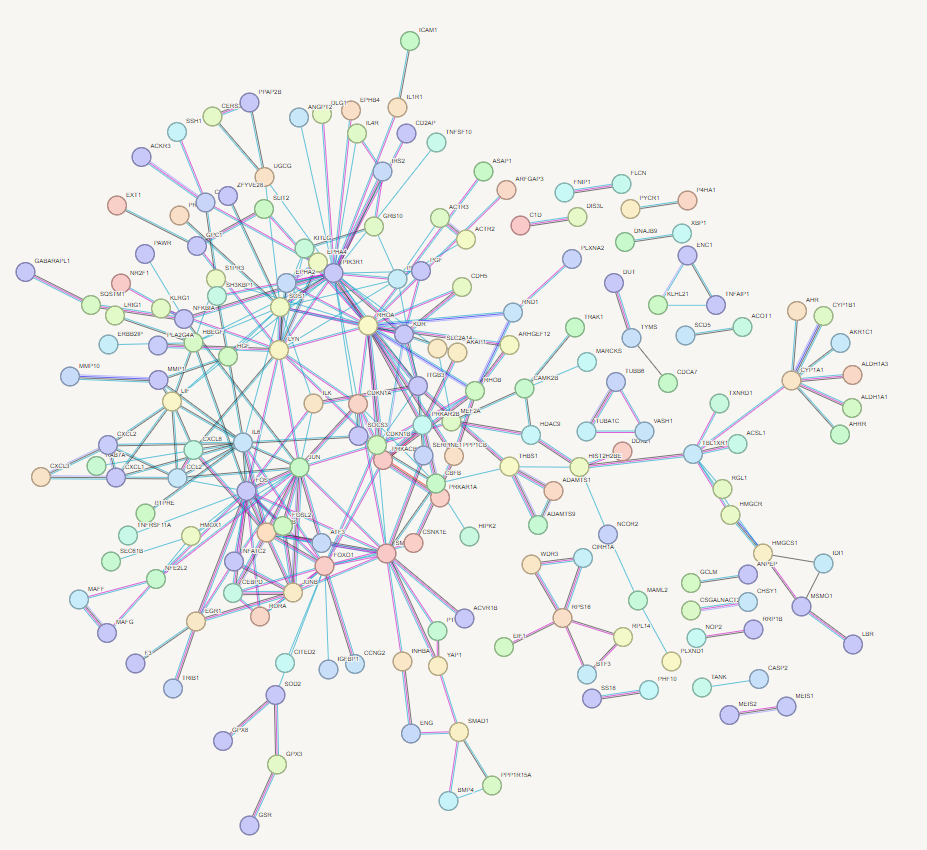 STRING-db Network
STRING-db Network
Now play and refine your network - try clusting using 3 clusters
STRING Panopto
Semantic similarity with Revigo
Revigo can take long lists of Gene Ontology terms and summarize them by removing redundant GO terms using semantic similarity. The input you need is a list of GO terms in the format GO:[NUMBER] a tab and the associated p-value.
1. Export GO terms and P-values
1A. gprofiler
Under the detailed results menu there is a CSV icon which when clicked can be used to export your enriched terms as a CSV which can then be imported into excel. You can use the associated setting button (the cog symbol next toi the CSV) to select only GO terms to export for this exercise.
 gprofiler export
gprofiler export
You will then need to copy column C and D into Revigo
1B. DAVID
After you have completed the functional analysis select < Gene_ontology > GOTERM_BP_DIRECT > Chart >
now Select < Download File >
 DAVID Go Download
DAVID Go Download
This will either display the enrichment table into the browser window or ask for a save location depending on your browser settings. If you are not asked for a save location right hand click the displayed table and select Save as and save to a appropriate location as a text file. This text file can be opened/imported into excel. You will file the GO term is concatenated with the GO description in Column B. To split this insert a blank column after column B, then select column B and select menu option < Data > Test to columns >. Select < Delimited > Next >_ and use the radio button to select other and add a ~_ to the box directly to the right of this option. Now click < Next and Finish >. You will see the GO term in now in Column B and the P-value in column F. Select these columns and paste them into Revigo.
You should now repeat this process for Molecular Function and Cell Component Terms.When all the data is merged you can paste the GO term and P value into Revigo.
2. Revigo data entry
Enter GO terms and P-values into Revigo - they should be in format
Term PValue
GO:0045892 7.75E-06
GO:0006694 3.29E-04Leave the default settings and select < Start Revigo >
3. Review Revigo Results
For each GO term category Revigo will generate a Scatterplot, Table, 3D scatter plot, interactive Graph and Tree Map. Note: at the bottom of each plot there are export options for R and other formats _.
The most intuitive format is are the Tree Maps (see below) whilst the Scatterplot output table, which include terms like ‘Frequency and Uniqueness’ can be used to create networks in Cytoscape.
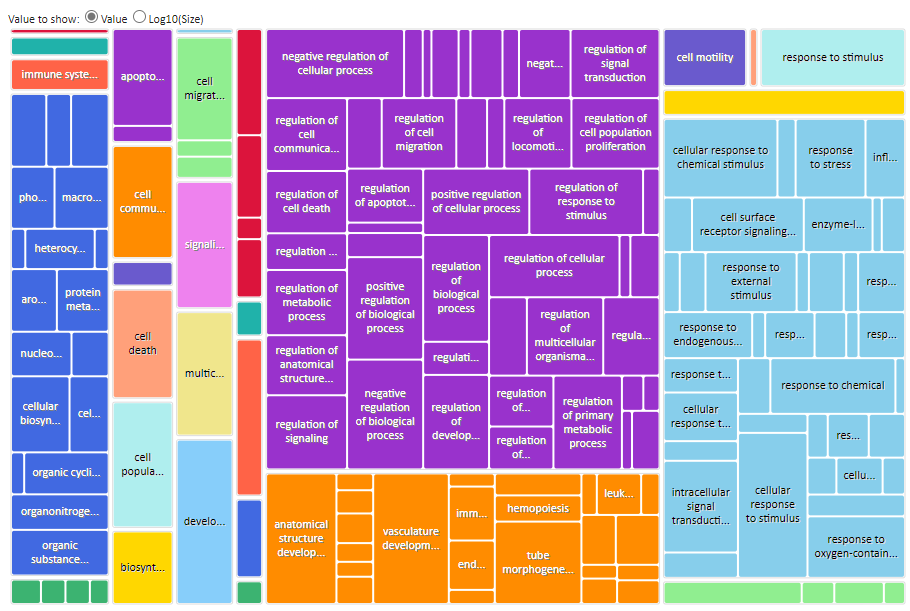 Revigo BP TreeMap
Revigo BP TreeMap